| 解説 | グラフ |
| 定常的なユーザCPUとシステムCPU使用が認められます。この区間では、他のCPUを使用するプロセス(スレッド)は待たされます。 | 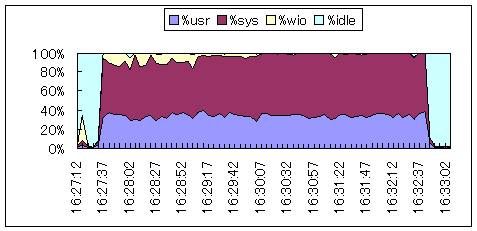 シナリオ番号:2 os(部分) |
CPUボトルネックの原因を探る
表1.確認ポイントと項目
| No | 確認ポイント | コマンドとオプション | 確認する項目 |
| ① | ユーザとシステムCPUの合計が平均で70〜80%以上か? | sar -u | %usr、%sys |
| vmstat | us、sy | ||
| mpstat | usr、sys | ||
| ② | CPU待ちはあるのか? | sar -q | runq-sz |
| vmstat | r | ||
| ③ | ユーザとシステムCPUの比率は? | sar -u | %usr、%sys |
| vmstat | us、sy | ||
| ④ | どのプロセスがCPUを消費しているのか? | prstat | CPU |
| ps -efl | -efcl | -efcLl | TIME | LTIME | ||
| timex/ptime | real、user、sys | ||
| accton(採取開始と停止) acctcom -f -m -t(編集) |
REAL、USER、SYS | ||
| ⑤ | 複数CPUの場合、排他制御のロック待ちになっていないか? | mpstat | smtx |
| ⑥ | システムコール数は妥当か? | sar -c | scall/s |
| vmstat | sy | ||
| ⑦ | リード・ライトシステムコールの比率はどうか? | sar -c | sread/s、swrit/s |
| ⑧ | プロセス実行のシステムコールはどうか? | sar -c | fork/s、exec/s |
| ⑨ | プロセス間通信(IPC)システムコールはどうか? | sar -m | msg/s、sema/s |
| ⑩ | コンテクストスイッチは妥当か? | sar -w | pswch/s |
| vmstat | cs | ||
| ⑪ | ディスク入出力との関係はどうか? | sar -d | %busy、avserv、avwait |
| iostat -xdn | %b、svc_t、wait | ||
| ⑫ | インタラプトが多発していないか? | vmstat | in |
| vmstat -i | interrupt | ||
| mpstat | intr | ||
| ⑬ | NFSの状態はどうなっているのか? | nfsstat | |
| ⑭ | ディスク入出力待ちが大きいか? | sar -u | %wio |
定常的に、ユーザCPU使用率%usrと、システムCPU使用率%sysの合計が70〜80%の場合、CPU資源不足が考えられます。%usrと%sysの合計が100%であっても、CPU待ち(後述②)による処理の遅れが無い場合は問題ありません。これはCPUリソースを充分に消費している、すなわちCPUの使用効率が良いということになります。技術計算や配列操作の多いプログラムはこの傾向が強くなります。CPU待ちが高い場合、CPU資源が不足していると判断します。例では約5分間の高いCPU消費が見られます。この経過時間(elapsed time)が許容範囲かどうかが判断基準です。
| 解説 | グラフ |
| 定常的なユーザCPUとシステムCPU使用が認められます。この区間では、他のCPUを使用するプロセス(スレッド)は待たされます。 | シナリオ番号:2 os(部分) |
図1.CPU使用率
プロセス、またはスレッドが、メモリにロードされて実行可能であるのに、CPUの制御が与えられない場合、待ち行列にキューされます。このキューを示す値がsar コマンド-qオプションで表示される runq-sz です。vmstatコマンドでは r に相当します。参考文献1はCPU数の2倍以上、参考文献2はCPU数の4倍以上と、文献によって問題とする値に違いがあります。本コンテンツでは、CPU数プラス2以上を問題と考えます。理由としては、単一CPUの場合、そのCPU上でプロセス(A)が実行されているところに、次のCPUを使用するプロセス(B)が実行された場合、(B)は待ち行列に入れられるからです。新たなプロセス(B)のCPU処理は、先のプロセス(A)が中断されるまで待たされます。
| 解説 | グラフ |
| 複数のプロセスが待たされていることを示しています。トランザクション処理ではレスポンスが低下する要因になります。 | 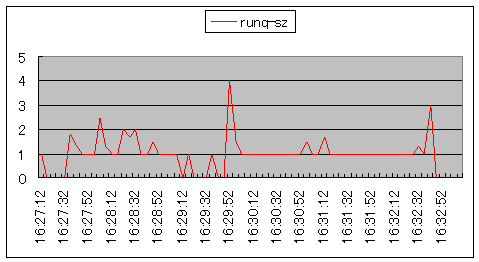 シナリオ番号:2 os(部分) |
図2.CPUの待ち
過去、%usrと%sysのCPU使用比率は、1対1が理想と言われていました。この比率は、プログラムの処理方法によって大きな違いが出て来ます。このため、最近は、必ずしも1対1の比率では無くなっています。プログラムが技術計算、多くの配列操作や、レジスタを多用している結果、%usrが高い値を示している場合は問題ありません。また、NFSデーモンのように、カーネルCPUを多く使用するプロセスが実行されている場合も問題ではありません。例え、%usrと%sysの合計が100%であっても、CPU待ち(前述②)による処理の遅れが無い場合も問題ありません。これは、CPU資源を充分に消費している、すなわちCPU使用効率が良いということになります。判断基準としては、プログラムのロジックと相反する動作が認められる場合に問題となります。本来どうであるかを予め知っておくことが大切です。結果として、CPU待ちが高い場合、CPU資源不足と判断できます。
| 解説 | グラフ |
| in.ftpd(サーバFTPデーモン)による動作です。%sysのみ使用されています。最初の山はSolaris←Linux(ftp起動側からファイルput)、次の山はSolaris→Linux(ftp起動側からファイルget)の振る舞いです。 | 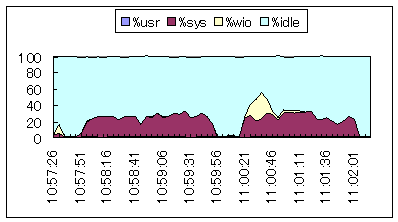 シナリオ番号:3 os |
| CPU使用率は100%ではないにもかかわらず、CPU待ちが発生しています。これは、ユーザとカーネルスレッド、割り込みスレッド等の競合と考えられます。 | 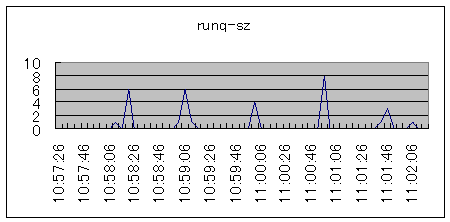 シナリオ番号:3 os |
図3.片寄ったCPU使用
デーモンのような常にメモリ上にロードされているプロセスを常駐プロセスと呼びます。常駐プロセスのCPU消費は、psやprstatコマンドで調べます。起動・終了するプログラムで、実行中にCPU消費時間を把握することが出来ないプロセスを非常駐プロセスと呼びます。非常駐プロセスのCPU消費は、timexやptimeコマンドで時間を調べます。timexやptimeコマンドが使用出来ない場合、プロセスアカウントを採取し、編集情報から値を得ます。表4.1に、これらステータスの採取方法をまとめました。
表4.1 プロセスのCPU消費時間を調べる
| プロセス動作の区分 | チェックするポイント | 注意点 |
| 常駐しているプロセス。 | prstatコマンドを実行してCPUフィールドを確認するか、またはpsコマンドを定期的に発行して、そのプロセスのTIME 、またはLTIMEフィールドの増加を見て下さい。 | prstatコマンドは画面に表示される上位コマンドのCPU使用率を確認します。psコマンドの発行間隔(サンプリングインターバル)を例えば5秒とした場合、採取の開始と終了時の誤差が大きくなることに注意して下さい。並行してOSの性能情報を採取しておき、CPU以外のリソースに問題があるのかどうかを確認出来るようにして下さい。 |
| 起動・終了する非常駐プロセス。 | timex、またはptimeコマンドを、目的のコマンドの先頭にセットして計測します。目的のコマンドが終了するとreal、sys、およびuserの時間が表示されます。それらの時間を確認して下さい。 | 並行してOSの性能情報を採取しておき、CPU以外のリソースに問題があるのかどうかを確認できるようにして下さい。 |
| 起動・終了するプロセスですが、コマンド起動時にtimex、ptimeが使えないもの。例えば、GUIより起動されるコマンドや、そのコマンドを起動するスクリプト類を修正出来ないようなものが該当します。 | プロセスアカウンティングをacctonコマンドでオンし、目的の処理を実行します。所定の時間経過後、プロセスアカウンティングをオフし、acctcomコマンドで情報を編集して確認して下さい。 | 同上。 |
複数CPUが構成されているシステムでは、経過時間にCPU枚数を掛けたものが合計のCPU時間です。この合計に対して、常駐プロセスと非常駐プロセスのCPU使用時間がどうであるかが判断の基準になります。この式は次の通りになります。
CPU数×時間×平均のCPU使用率(パーセンテージ)≒常駐プロセスのCPU使用時間合計+非常駐プロセスのCPU使用時間合計
プログラムのロジックと相反する動作が認められる場合に問題となります。本来どうであるかを予め知っておくことが大切です。結果として、CPU待ちが高い場合、CPU資源不足と判断します。
| 解説 | グラフ |
| ORACLEチェックポイントのバックグラウンドプロセスです。psコマンドの出力、TIME項目から抽出しました。ORACLE開始後、3秒のCPUを消費しています。 | 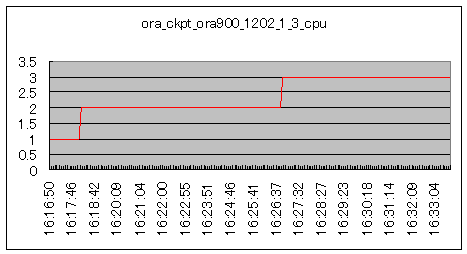 シナリオ番号:2 process(部分) |
図4.常駐プロセスのCPU使用時間
表4.2 prstatの表示例
| 解説 | データ |
|
表4.3 非常駐プロセスのCPU使用時間
| 解説 | データ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| プロセスアカウント情報から、 command: コマンド名 userid: ユーザID elaps: エラプス時間合計(秒) callcount: 呼び出し回数 totalcpu: CPU合計(秒) rate%: 全体に占めるCPU時間の割合 syscpu: システムCPU(秒) sysmsec: コマンド単位のシステムCPU(ミリ秒) usercpu: ユーザCPU(秒) usermsec: コマンド単位のユーザCPU(ミリ秒) にまとめたものです。 usercpuで逆ソートし、0.3秒以上をリストしました。 acctcomコマンドの出力から、コマンド名の出現回数をカウントするとともに、当該コマンド名のREAL、CPU部分の時間を累積し、最後に、「累積値を出現回数で割った値」がsysmsecとusermsecです。 |
|
マルチスレッドや、複数CPUの環境では、メモリ内容を更新する際、排他制御によって一貫性を保つ仕組みを持っています。これを排他制御(ミューテックスロック)と呼びます。CPUがラッシュ状態になると、排他制御が頻繁に発生し、ロック待ちが発生することがあります。ロック待ちを示す値はmpstatコマンドで表示される項目smtxです。参考文献1では500以上、参考文献2ではCPU数×250倍を問題としています。もしこの値が異常に高い場合に、ハードウェア的なシステム増強を検討する際、CPUの枚数を増やすのではなく、CPUそのものを速いもの(例えばクロック数の大きいもの)にすべきです。この理由は、smtxが高い状態でCPU枚数を増やすと、ロック待ちの機会が指数階乗的に増加するからです。
| 解説 | グラフ |
| 単一CPUでもこのような値が記録されることがあります。ユーザとカーネルスレッド、またはユーザと割り込みスレッドの競合が発生しているものと考えられます。 | 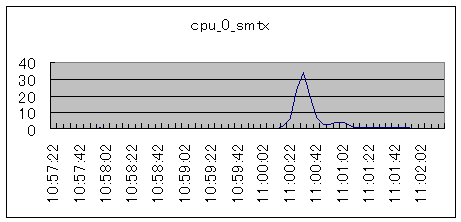 シナリオ番号:3 cpu |
図5.排他ロック
あらゆるシステムコールの秒あたり回数は、sarコマンド-cオプションのscall/sで示されます。scall/sは、リード・ライト、プロセス起動・実行、セマフォ制御などのシステムコール全部の秒あたり実行数が含まれます。プログラムの性質、アプリケーションの作り等で大きな差が出ます。このため、妥当性を判断するには、通常どのような値であるのか、予め知っておくことが大切です。
| 解説 | グラフ |
| 15:44:43より、ddコマンドのbs=16384で1ギガバイトのファイルを作成しました。波が低いのでやや見づらいです。15:46:33より、ddコマンドのbs=512で1ギガバイトのファイルを作成しました。ブロック化係数が変化することで、システムコール数が大幅に増加しています。 | 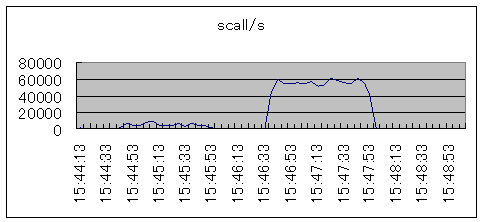 シナリオ番号:4 os |
図6.システムコール
一般的に、バッチ処理は大量のデータを処理するため、ディスクのリード・ライトシステムコールが多いです。トランザクション処理は、ディスク入出力を最適化することによって、リード・ライトのシステムコールは抑えられるべきです。このように、アプリケーションの動作や処理の違いによって、システムコールに占めるリード・ライトシステムコールの率は変わってきます。したがって、リード・ライトシステムコール比率の妥当性は、通常どのようなものであるかを知っておくことが大切です。プログラムのロジックと相反する動作が認められる場合に問題となります。
| 解説 | グラフ |
| ddコマンドで、1ギガバイトのファイルを作成しました。ブロックサイズを示すbsパラメタに16384を指定することにより、ブロックサイズは16384バイト/1ブロックとなります。リード・ライトのシステムコールは約800回/秒の水準になります。この結果、scall/sに占めるリード・ライトのシステムコール比率は43パーセントになりました。 | 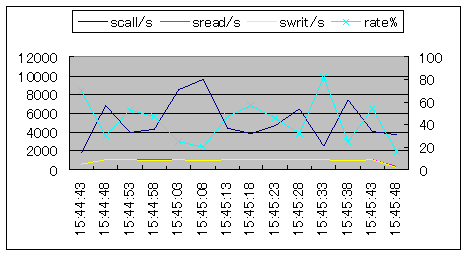 シナリオ番号:4 os(部分) |
| ddコマンドで、1ギガバイトのファイルを作成しました。ブロックサイズは、512バイト/1ブロックとなります。リード・ライトのシステムコールは約28000回/秒の水準になります。この結果、scall/sに占めるリード・ライトのシステムコール比率は96パーセントになりました。 | 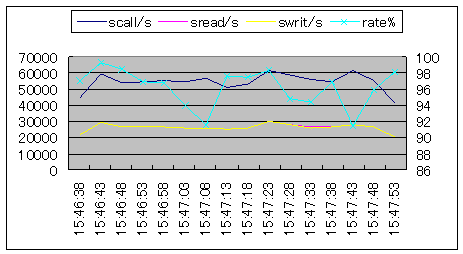 シナリオ番号:4 os(部分) |
図7.リード・ライトシステムコールの比率
UNIXでは、新たなプロセスを生起する時、forkシステムコールによって子プロセスを発生させ、続いて、発生した子プロセス自身が、目的の実行プログラムをexecシステムコールによって起動します。この過程で、メモリを始めとして、ファイルオープン識別子、各種の制御テーブル等を大量に割り当てることから、処理に多くのコストがかかることが知られています。シェルスクリプトを中心にした処理では、fork/execシステムコールが高くなります。マルチスレッド環境は、このプロセス生起の手順とは別の方法で、スレッドを発生させることにより、低コストで目的の処理を実行する仕組みを提供しています。このため、TPモニターのようなトランザクション処理システムは、スレッド化された構造を持つことが多く、fork/execシステムコールの比率が低いようです。プログラムの性質、アプリケーションの作り等で大きな差が出ます。このため、妥当性を判断するには、通常どのような値であるのか予め知っておくことが大切です。
| 解説 | グラフ |
| 16:18:34から約30秒間、および16:27:30からの5分間はシェルスクリプト、コマンドを多用したプログラムが実行されています。fork/sとexec/sの比率が高くなっています。16:16:44から約90秒はddコマンドによるリード・ライトシステムコールです。 | 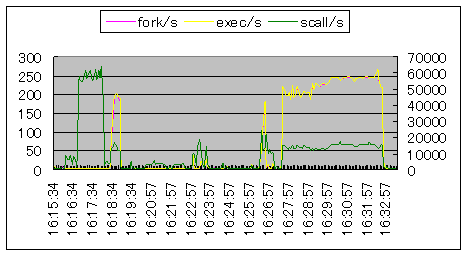 シナリオ番号:2 os |
図8.プロセス実行のシステムコール
プロセス間通信(IPC:Inter Process Communication)は、プロセスとプロセスの間でデータをやり取りする仕組みで、System V IPCと呼ばれています。IPCの機能は、共有メモリ、メッセージキュー、およびセマフォの3種類です。共有メモリは、同じメモリ空間を別プロセスが読み書きできる機能です。メッセージキューは、メッセージと呼ばれるデータの単位をプロセス間で送受信する機能です。セマフォ(semaphore:腕木信号機のことです)はプロセス間でセマフォ値と呼ばれる信号の交換を行うことで、プロセスの同期を取ったり、排他制御を行う機能です。TPモニターのようなトランザクション処理システムや、データベースソフトウェアで多く使用されています。sarコマンド-mオプションは、メッセージキューとセマフォの秒あたり操作数を表示します。システムコールに占めるIPCコールの割り合いが多い場合、CPU資源を多く使用することがあります。他のシステムコールと同様に、プログラムの性質、アプリケーションの作り等で大きな差が出ます。このため、妥当性を判断するには、通常どのような値であるのか予め知っておくことが大切です。また、IPC関連のチューニングは大切です。
| 解説 | グラフ |
| ORACLE STATSPACKの起動と、レポート作成時に、秒あたりのセマフォ操作数が高くなっています。 | 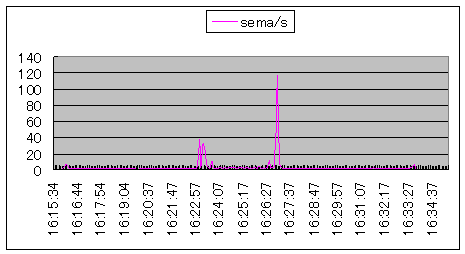 シナリオ番号:2 os |
図9.プロセス間通信(IPC)
プロセス(スレッド)が他のプロセス(スレッド)、またはカーネルにCPU制御を移すことをコンテクストスイッチと呼びます。システムコールが多用されていたり、割り込みが多く発生したような場合、関連してコンテクストスイッチの値が高くなることがあります。プログラムの性質、アプリケーションの作り、および機器構成等で大きな差が出ます。このため、妥当性を判断するには、通常どのような値であるのか、予め知っておくことが大切です。
| 解説 | グラフ |
| ORACLEのセマフォ制御時が最もコンテクストスイッチが高くなっています。 | 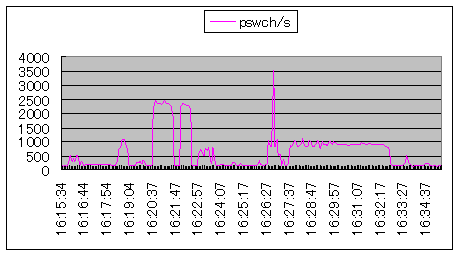 シナリオ番号:2 os |
図10.コンテクストスイッチ
ユーザプロセスがCPU上で計算処理を行っている最中、それより前にライトされたデータをディスクに書き込み中、という場面は多くあります。ディスクにデータ転送を終えて書き込みが終了すると割り込みが起き、割り込み処理が行われます。そのCPU上で行われていたユーザの計算処理は、一旦中断します。割り込み処理がまたたく間に終了し、中断していたユーザCPUの処理が継続する…CPUは100%使用され、ディスク入出力はその間に終わっているというのが並行処理の理想です。一方、CPUの計算処理を終え、処理結果データをディスクに書き込む。続いて、ディスクの書き込み終了を待っている。即ち、入出力待ち%wioが発生する。このような状況は、CPU処理の観点からもったいないものです。このタイムラグを抑えるために、ディスクバッファキャッシュの機構があります。次に、ブロック化係数の違いで%wioを記録する状態と、CPUをより多く使用する顕著な例を示します。
| 解説 | グラフ |
| 15:44:43は、ddコマンドのbs=16384で1ギガバイトファイルを作成した時のCPU使用状況です。%wioが発生しており、ディスクの待ちが発生しています。15:46:33は、ddコマンドのbs=512で1ギガバイトファイルを作成した時のCPU使用状況です。%usrと%sysが高くなっています。 | 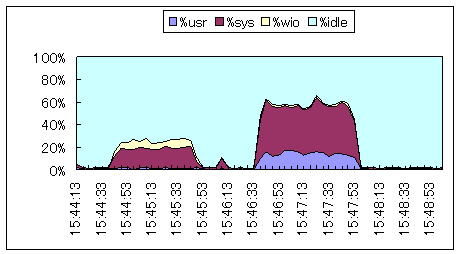 シナリオ番号:4 os |
| %usrと%sysの高まりは、リード・ライトシステムコールと、データのブロック詰めによるものです。エラプス時間は約20秒余分にかかっています。bs=16384がCPUリソースを消費していないので得だと分かります。%wioが無くなるのが理想ですが… | 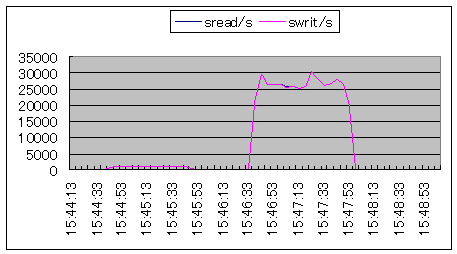 シナリオ番号:4 os |
| ディスクのビジーです。 ブロックサイズが大きい場合=%busyは高い ブロックサイズが小さい場合=%busyは低い となります。 |
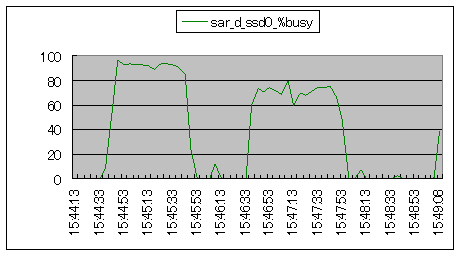 シナリオ番号:4 disk |
図11.ディスク入出力との関係
滅多にないことですが、割り込みが急激に発生した結果スローダウンになることがあります。ハードウェアトラブルか、またはネットワーク攻撃の可能性があります。
| 解説 | グラフ |
| CPU0の割り込みです。この例は、ftpで他の機器からget要求が来たものです。本シナリオのサンプリングインターバルは5秒ですから、秒あたり5〜600パケットが送受信されています。ネットワークのみならず、ディスク関連のインタラプトも数えられます。SYN flood等の攻撃では、このような数ではなく、とんでもない数になります。 | 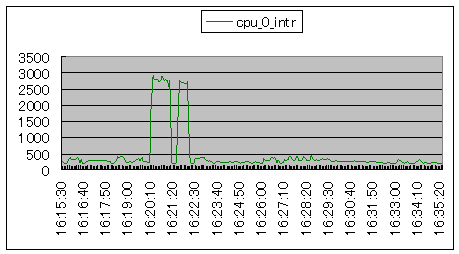 シナリオ番号:2 cpu |
| 時計はいつも安定しています… |  シナリオ番号:2 cpu |
図12.インタラプト
N/A
%wioが定常的に30パーセントを超えると、ディスク入出力、またはメモリに何らかの問題があります。まず、「ディスク入出力」をご覧下さい。
| 解説 | グラフ |
| 16:02頃から16:04頃、および16:05頃から16:06:30頃まで高い%wioが記録されています。本シナリオでは、メモリ不足が原因でページングが頻繁になり、ディスク入出力が高負荷になっているものです。 | 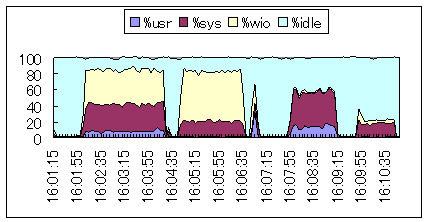 シナリオ番号:7 os |
Copyright (C) 2004 by The Art of Computer Technologies, Corp. All rights reserved.